DDPM
DDPM
- DDPM就是指的是一般而言的Diffusion。DDPM是先河。
- DDPM forward 就是加noise, backward就是denoise
作为参数的Diffusion模型。backward denoiser,生成器。
forward process function。q用Gaussian Distribution来model加noise的过程
- 用Reparameterization trick, 可以一步从 得到
step size
假设总共需要1000步生成一张图片
step size = 1: 用1000步生成
step size = 10: 用100步生成
Classifier guidance
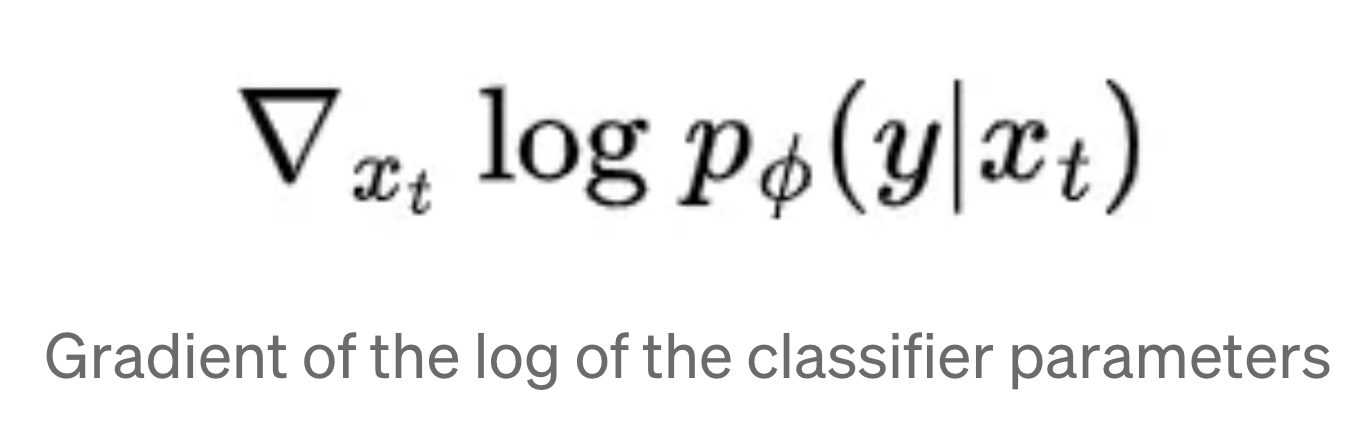
似乎不常用。用classify时的gradient?来feed to the diffusion model
Classifier-free Guidance
读了一下这个blog

觉得这个图很好
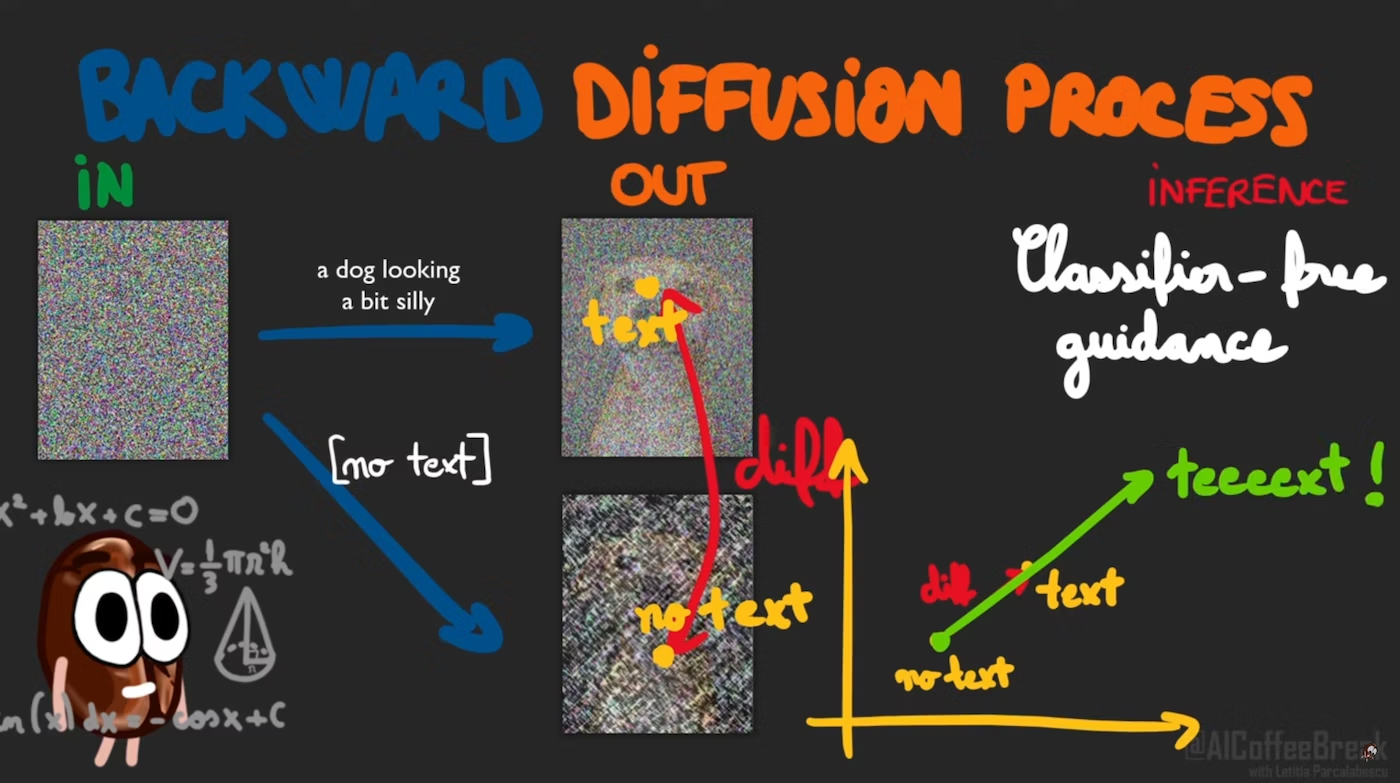
也就是说
-
guide是指输入prompt时的输出 - 不输入prompt时的输出的方向 - 称为 Classifier-free 是因为没有用任何的Classifier,只用了比起没有text时的差分
-
CFG Scale就是指这里用了多少比率
- Stable Diffusion 是7.0,感觉真是个奇妙的数字。
DDIM
DDIM

- 最主要的区别在于DDIM用了non-Markovian
- 速度快,效果会差一点。不需要重新训练模型
- DDIM variance 的时候,没有noise,是纯DDIM (deterministic)。对立面是DDPM。可以interpolate两种手法。
DDIM scale
1 = DDPM = probablistic
0 = DDIM = deterministic
DDIM inversion?
Defined in:

Abstract
Recent large-scale text-guided diffusion models provide powerful image generation capabilities. Currently, a massive effort is given to enable the modification of these images using text only as means to offer intuitive and versatile editing tools. To edit a real image using these state-of-the-art tools, one must first invert the image with a meaningful text prompt into the pretrained model's domain. In this paper, we introduce an accurate inversion technique and thus facilitate an intuitive text-based modification of the image. Our proposed inversion consists of two key novel components: (i) Pivotal inversion for diffusion models. While current methods aim at mapping random noise samples to a single input image, we use a single pivotal noise vector for each timestamp and optimize around it. We demonstrate that a direct DDIM inversion is inadequate on its own, but does provide a rather good anchor for our optimization. (ii) Null-text optimization, where we only modify the unconditional textual embedding that is used for classifier-free guidance, rather than the input text embedding. This allows for keeping both the model weights and the conditional embedding intact and hence enables applying prompt-based editing while avoiding the cumbersome tuning of the model's weights. Our null-text inversion, based on the publicly available Stable Diffusion model, is extensively evaluated on a variety of images and various prompt editing, showing high-fidelity editing of real images.
由于没有对输入的text的embedding和模型的weight做optimization,即使做了 null-text inversion 之后仍可以继续修改text
- unconditional textual embedding 指的是空字符串作为输入时的textual embedding。在classifier-free guidance的过程中, 用作guidance的方向。
- Guided Diffusion Model指的是什么? ⇒ 应该在这是指 text-guided + classifier-free guided。
On top: We first apply an initial DDIM inversion on the input image which estimates a diffusion trajectory (top trajectory). Starting the diffusion process from the last latent code results in unsatisfying reconstruction (bottom trajectory) as the intermediate codes become farther away from the original trajectory. We use the initial trajectory as a pivot for our optimization which brings the diffusion backward trajectory closer to the original image.
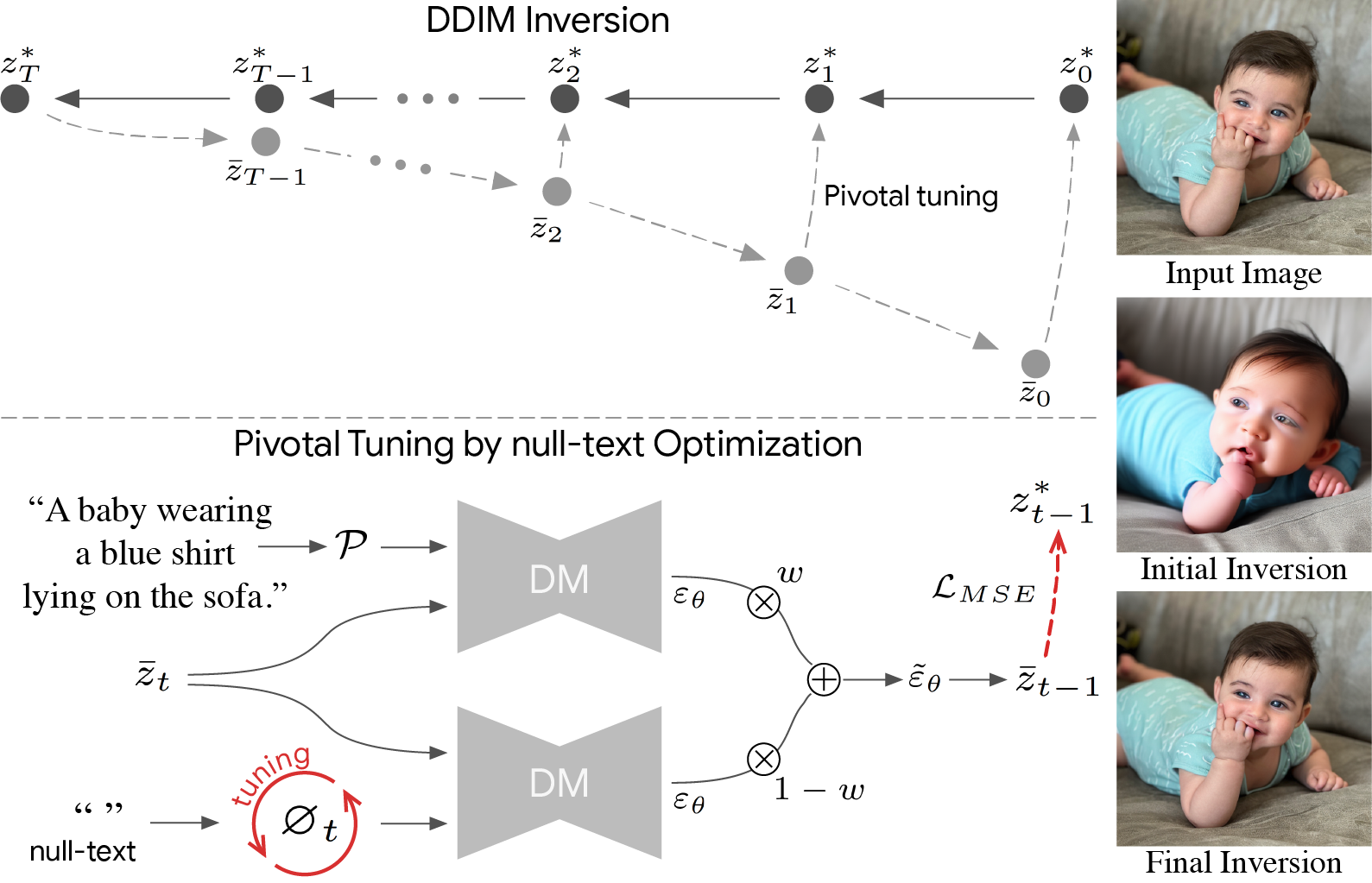
Bottom: null-text optimization for timestamp t. Recall that classifier-free guidance consists of performing the noise prediction twice – using text condition embedding and unconditionally using null-text embedding ∅ (bottom-left). Then, these are extrapolated with guidance scale w (middle). We optimize only the unconditional embeddings ∅t by employing a reconstruction MSE loss (in red) between the predicated latent code to the pivot.
- 我一开始以为上面的轨迹是DDPM forward。所以什么是DDIM inversion呢?
Editing使用了一个叫Prompt-to-Prompt的方法
